Druid —— PB 级的 OLAP 数据实时查询引擎
本文共 536 字,大约阅读时间需要 1 分钟。
Druid 是为大型数据集上实时探索查询的引擎,提供专为 OLAP 设计的开源分析数据存储系统,它的设计意图是在面对代码部署、机器故障以及其他产品系统遇到不测时能保持100%正常运行。它也可以用于后台用例,但设计决策明确定位线上服务。
数据流:
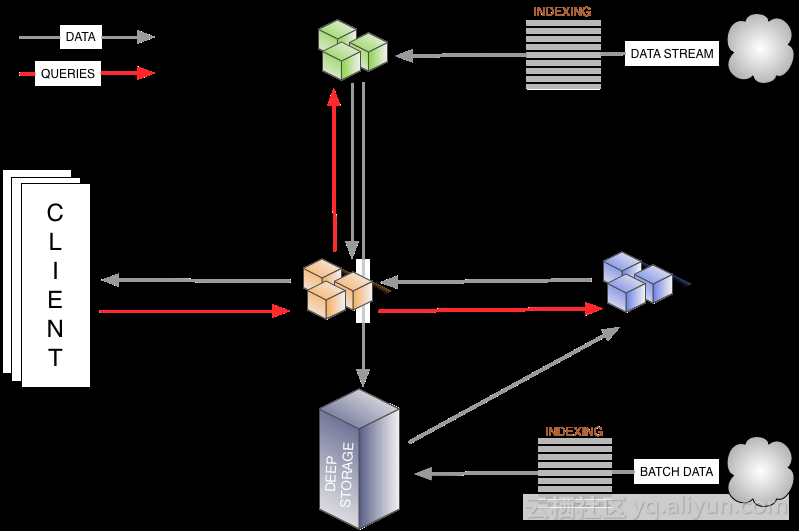
集群架构:
主要特性:
- 为分析而设计——Druid是为OLAP工作流的探索性分析而构建。它支持各种filter、aggregator和查询类型,并为添加新功能提供了一个框架。用户已经利用Druid的基础设施开发了高级K查询和直方图功能。
- 交互式查询——Druid的低延迟数据摄取架构允许事件在它们创建后毫秒内查询,因为Druid的查询延时通过只读取和扫描优必要的元素被优化。Aggregate和 filter没有坐等结果。
- 高可用性——Druid是用来支持需要一直在线的SaaS的实现。你的数据在系统更新时依然可用、可查询。规模的扩大和缩小不会造成数据丢失。
- 可伸缩——现有的Druid部署每天处理数十亿事件和TB级数据。Druid被设计成PB级别
文章转载自 开源中国社区 [
你可能感兴趣的文章